
Genes and transcripts in Ensembl Plants, Demo
Demo: Exploring genes and transcripts in Ensembl Plants
You can find out lots of information about Ensembl genes and transcripts using the browser. If you’re already looking at a region view, you can click on any transcript and a pop-up menu will appear, allowing you to jump directly to that gene or transcript.

Alternatively, you can find a gene by searching for it. You can search for gene names or identifiers, and also phenotypes or functions that might be associated with the genes.
We’re going to look at the Arabidopsis thaliana PAI1 gene. From plants.ensembl.org, type PAI1 into the search bar and click the Go button.
The gene tab
Click on PAI1 from the search hits. The Gene tab should open:
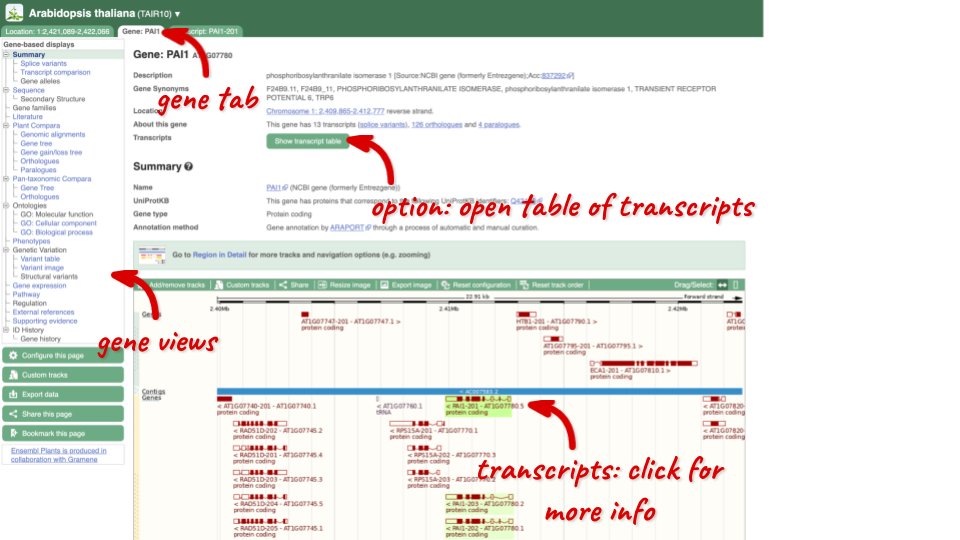
This page summarises the gene, including its location, name and equivalents in other databases. At the bottom of the page, a graphic shows a region view with the transcripts. We can see exons shown as blocks with introns as lines linking them together. Coding exons are filled, whereas non-coding exons are empty. We can also see the overlapping and neighbouring genes and other genomic features.
There are different tabs for different types of features, such as genes, transcripts or variants. These appear side-by-side across the blue bar, allowing you to jump back and forth between features of interest. Each tab has its own navigation column down the left hand side of the page, listing all the things you can see for this feature.
Let’s walk through this menu for the gene tab. How can we view the genomic sequence? Click Sequence at the left of the page.

The sequence is shown in FASTA format. The FASTA header contains the genome assembly, chromosome, coordinates and strand (1 or -1) – this gene is on the negative strand.

Exons are highlighted within the genomic sequence, both exons of our gene of interest and any neighbouring or overlapping gene. By default, 600 bases are shown up and downstream of the gene. We can make changes to how this sequence appears with the blue Configure this page button found at the left. This allows us to change the flanking regions, add variants, add line numbering and more. Click on it now.

Once you have selected changes (in this example, Show variants and Line numbering) click at the top right.
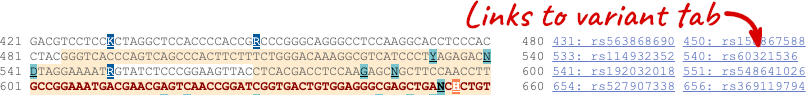
You can download this sequence by clicking in the Download sequence button above the sequence:
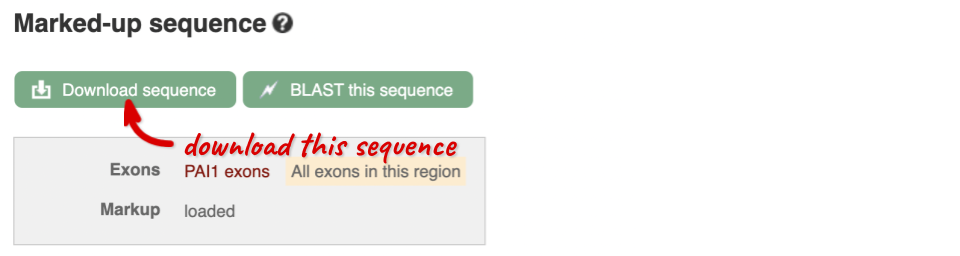
This will open a dialogue box that allows you to pick between plain FASTA sequence, or sequence in RTF, which includes all the coloured annotations and can be opened in a word processor. If you want run a sequence analysis tool, download as FASTA sequence, whereas if you want to analyse the sequence visually, RTF is best for this. This button is available for all sequence views.
To find out what the protein does, have a look at GO terms from the Gene Ontology consortium. There are three pages of GO terms, representing the three divisions in GO: Biological process (what the protein does), Cellular component (where the protein is) and Molecular function (how it does it). Click on GO: Biological process to see an example of the GO pages.
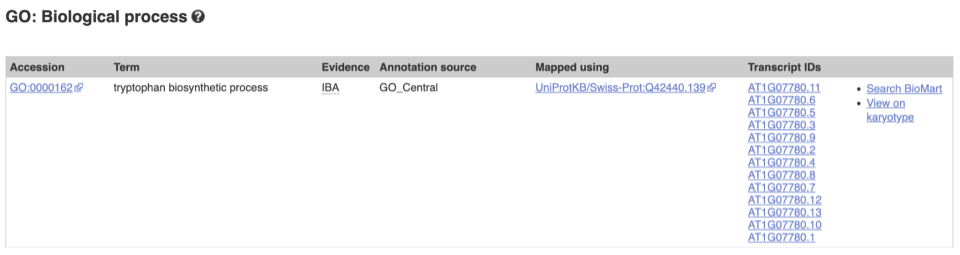
Here you can see the functions that have been associated with the gene. There are three-letter codes that indicate how the association was made, as well as links to the specific transcript they are linked to.
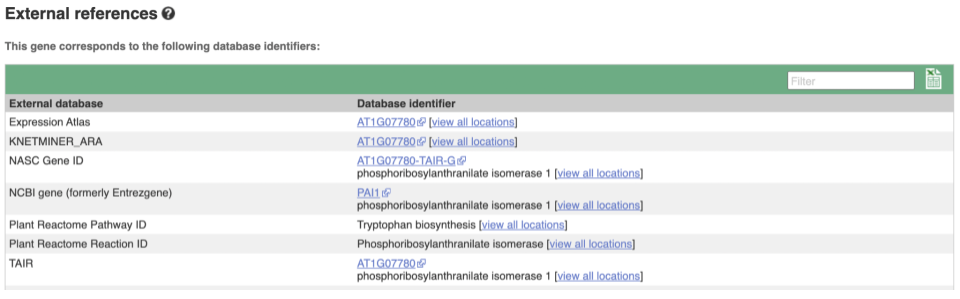
We also have links out to other databases which have information about our genes and may focus on other topics that we don’t cover, like Expression Atlas or UniProtKB. Go up the left-hand menu to External references:
Demo: The transcript tab
We’re now going to explore the different transcripts of PAI1. Click on Show transcript table at the top.
![]()
![]()
Here we can see a list of all the transcripts of PAI1 with their identifiers, lengths and biotypes. Click on the ID of the Ensembl Canonical transcript, PAI1-211.
You are now in the Transcript tab for PAI1-211. We can still see the gene tab so we can easily jump back. The left hand navigation column provides several options for the transcript PAI1-211 - many of these are similar to the options you see in the gene tab, but not all of them. If you can’t find the thing you’re looking for, often the solution is to switch tabs.
Click on the Exons link. This page is useful for designing RT-PCR primers because you can see the sequences of the different exons and their lengths.
![]()
You may want to change the display (for example, to show more flanking sequence, or to show full introns). In order to do so click on Configure this page and change the display options accordingly.
Now click on the cDNA link to see the spliced transcript sequence with the amino acid sequence. This page is useful for mapping between the RNA and protein sequences, particularly genetic variants.
![]()
UnTranslated Regions (UTRs) are highlighted in dark yellow, codons are highlighted in light yellow, and exon sequence is shown in black or blue letters to show exon divides. Sequence variants are represented by highlighted nucleotides and clickable IUPAC codes are above the sequence.
Next, follow the General identifiers link at the left. Just like the External References page in the gene tab, this page shows links out to other databases such as RefSeq, UniProtKB, PDBe and others, this time linked to the transcript or protein product, rather than the gene.
![]()
If you’re interested in protein domains, you could click on Protein summary to view domains from Pfam, PROSITE, Superfamily, InterPro, and more. These are all plotted against the transcript sequence, with the exons shown in alternating shades of purple at the top of the page. Alternatively, you can go to Domains & features to see a table of the same information.
![]()
![]()






