
Bulk export of data with BioMart, Demo
Follow these instructions to guide you through BioMart to answer the following query:
- What genes are found on chromosome 9, between 15274000 and 15300000 in Oryza sativa Japonica?
- What are the NCBI Gene IDs for these genes?
- Are there associated functions from the GO (gene ontology) project that might help describe their function?
- What are their cDNA sequences?
Click on BioMart in the top header of a plants.ensembl.org page to go to: plants.ensembl.org/biomart/martview
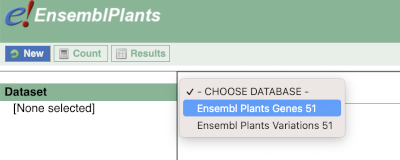
You cannot choose any filters or attributes until you’ve chosen your dataset. Your dataset is the data type you’re working with. In this case we’re going to choose human genes, so pick Ensembl Plants Genes then Oryza sativa Japonica Group genes from the drop-downs.
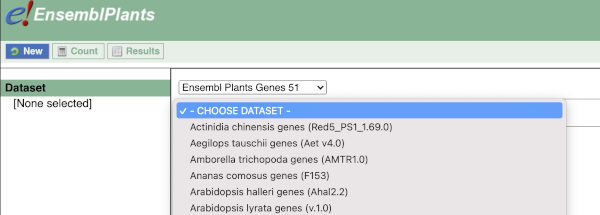
Now that you’ve chosen your dataset, the filters and attributes will appear in the column on the left. You can pick these in any order and the options you pick will appear.
Click on Filters on the left to see the available filters appear on the main page. You’ll see that there are loads of categories of Filters to choose from. You can expand these by clicking on them. For our query, we’re going to expand REGION.

Our input data is a locus, so we’re going to use the chromosome and coordinates filters. Choose chromosome 9 from the drop-down menu and paste in the start and the end coordinates (15274000 and 15300000). The filters will be autoselected when you add values to them and will appear in the left-hand column.
To check if the filters have worked, you can use the Count button at the top left, which will show you how many genes have passed the filter. If you get 0 or another number you don’t expect, this can help you to see if your query was effective.
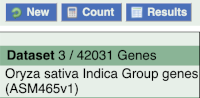
To choose the attributes, expand this in the menu. There are five categories for rice gene attributes. These categories are mutually exclusive, you cannot pick attributes from multiple categories. This means that we need to do two separate queries to get our GO terms and NCBI IDs, and to get our cDNA sequences.

The Ensembl gene and transcript IDs are selected by default. The selected attributes are also listed on the left.

We can choose the attributes we want by clicking on them. For our query, we’re going to select:
- GENE
- Gene Name
- EXTERNAL
- NCBI gene ID
- GO term accession
- GO term name
- GO term definition
We need to select the Gene Name in order to get back our original input, as this is not returned by default in BioMart. The order that you select the attributes in will define the order that the columns appear in in your output table.
You can get your results by clicking on Results at the top left.
The results table just gives you a preview of the first ten lines of your query. This allows the results to load quickly, so that if you need to make any changes to your query, you don’t waste any time. To see the full table you can click on View ## rows. You can also export the data to an xls, tsv, csv or html file. For large queries, it is recommended that you export your data as Compressed web file (notify by email), to ensure your download is not disrupted by connection issues.
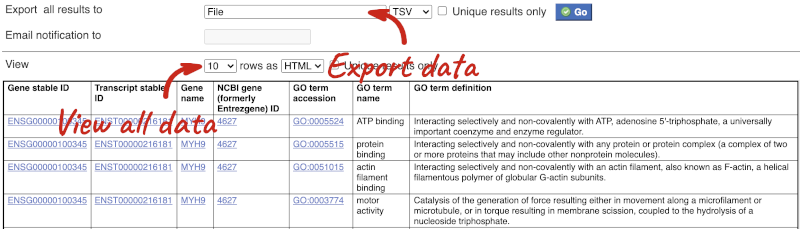
You can see multiple rows per gene in your input list, because there are multiple transcripts per gene and multiple GO terms per transcript.
To get the cDNA sequences, go back to the Attributes then select the category Sequences and expand SEQUENCES.
When you select the sequence type, the part of the transcript model you’ve chosen will be highlighted in the grpahic.
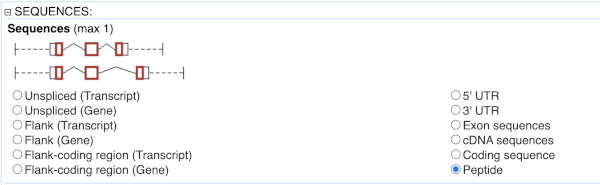
Choose cDNA sequences, then expand HEADER INFORMATION to add Gene Name to the header. Then hit Results again.

For more details on BioMart, have a look at this publication:
Kinsella, R.J. et al
Ensembl BioMarts: a hub for data retrieval across taxonomic space.
http://europepmc.org/articles/PMC3170168






