Demo - Pig genes and transcripts in Ensembl
Demo: The Gene tab
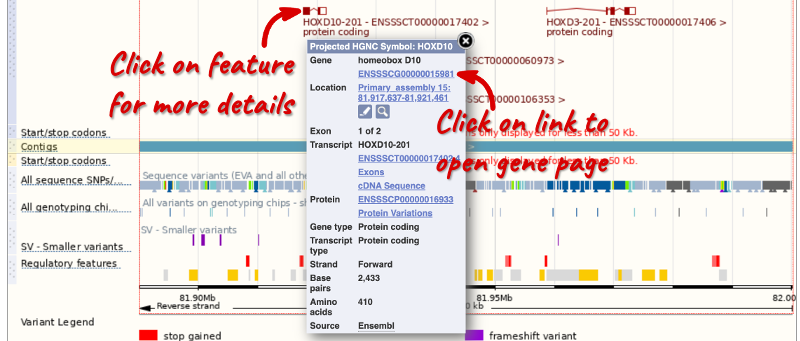
If you click on any one of the transcripts in the Region in detail image, a pop-up menu will appear, allowing you to jump directly to that gene or transcript.
Searching for a gene
Another way to go to a gene of interest is to search directly for it.
We’re going to look at the NSDHL gene in Sus scrofa (Pig). From www.ensembl.org, select Pig from the drop-down menu in the blue box. Enter NSDHL into the search box and click the Go button.
Your search results include hits in all available Pig genomes. You can filter your results by breed in the left-hand panel. We want to restrict our results to entries in the Pig reference only. Under Restrict breeds to: in the left, click on Pig reference.
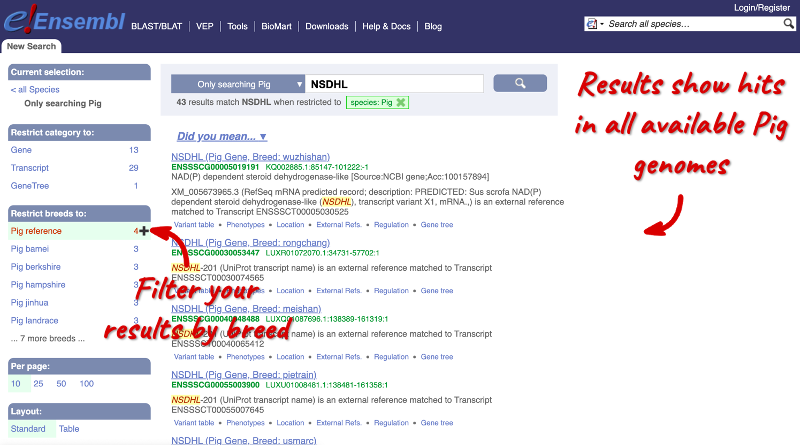
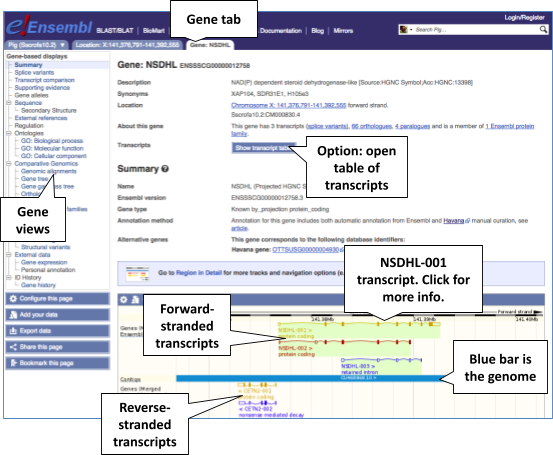
In your filtered search results, click on NSDHL (Pig Gene, Breed: reference) or the Ensembl ID ENSSSCG00005019191 to open the Gene tab:
Viewing the gene sequence
Let’s walk through some of the links in the left hand navigation column. How can we view the genomic sequence? Click Sequence in the left-hand panel.

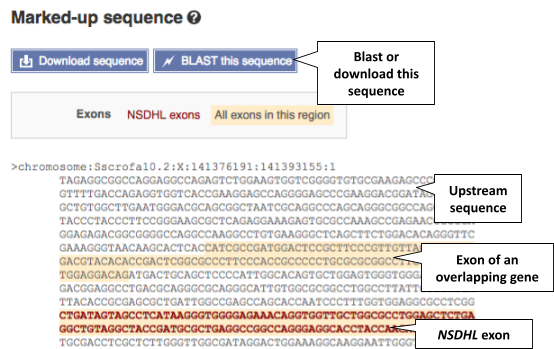
The sequence is shown in FASTA format. Take a look at the FASTA header:
>primary_assembly:Sscrofa11.1:X:123905599:123929717:1
The FASTA header always starts with a > followed by sequence information. Broken down, the information in the FASTA header is as follows:
>[primary_assembly:Sscrofa11.1]:[X]:[123905599]:[123929717]:[1]
- [primary_assembly:Sscrofa11.1] = name of the genome assembly
- = chromosome
- [123905599] = start coordinate
- [123929717] = end coordinate
- [1] = forward strand (-1 refers to reverse strand)
Exons are highlighted in orange within the genomic sequence. Variants can be added with the Configure this page button  found in the left-hand panel. Click on the button to open a pop-up menu. Add the options Show variants: Yes and show links and Line numbering: Relative to this sequence.
found in the left-hand panel. Click on the button to open a pop-up menu. Add the options Show variants: Yes and show links and Line numbering: Relative to this sequence.
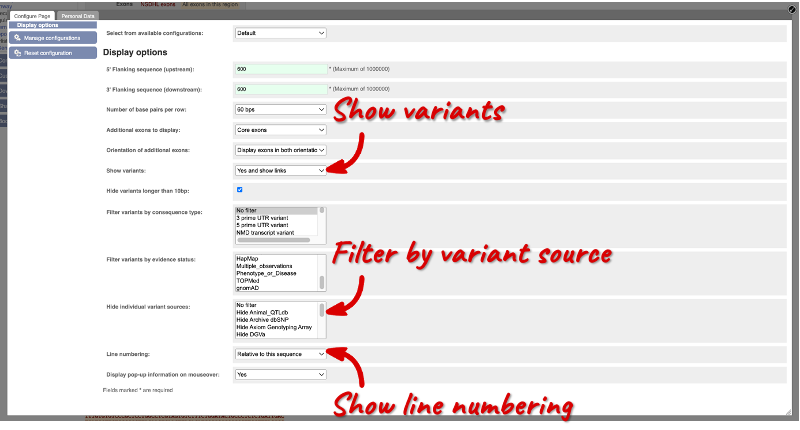
Save and close the pop-up menu by clicking on the check icon in the top right-hand corner.

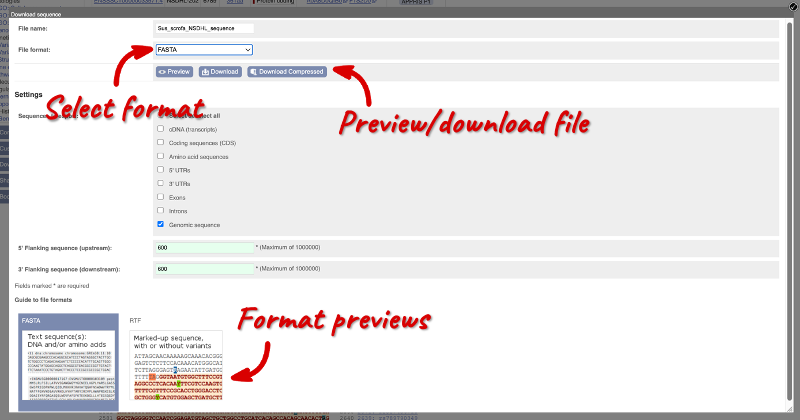
You can download this sequence by clicking in the Download sequence button  found above the sequence.
found above the sequence.
This will open a pop-up menu that allows you to pick the sequence format. You can download the sequence in plain FASTA or richt-text format (RTF), which includes all the coloured annotations and can be opened in a word processor. This button is available for all sequence views.
Viewing the gene function
To find out what the protein does, have a look at Gene Ontology (GO) terms from the Gene Ontology consortium. There are three categories of GO terms:
- Biological process (what the protein does)
- Cellular component (where the protein is)
- Molecular function (how it does it)
Click on GO: Biological process in the left-hand panel to view GO terms associated with NSDHL.

Viewing gene information in external databases
Can our gene be found in other databases? Click on External references in the left-hand menu.
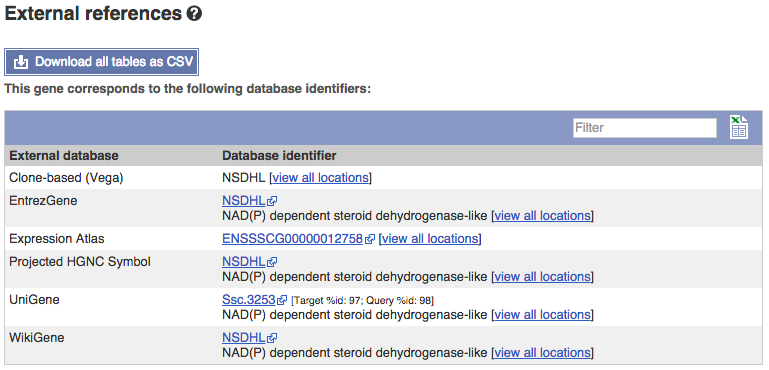
This page contains corresponding links to the gene in other projects, such as NCBI gene (formerly Entrezgene), Reactome gene and UniProtKB.
Demo: The Transcript tab
Let’s now explore one transcript/isoform/splice variant. Click on the Show transcript table button ![]() at the top of the page.
at the top of the page.
Have a look at the largest one, NSDHL-201.

If we were to only choose one transcript to analyse, we would choose this one because it has the Ensembl Canonical flag. The Ensembl canonical transcript is a single, representative transcript identified at every locus. You can read more about canonical transcripts in the Genebuild documentation page.
Click on the transcript ID ENSSSCT00000048661.3 to open the corresponding to view more information. This opens the corresponding Transcript tab. The left-hand menu provides several options for the transcript NSDHL-201. You can find any protein-related information in the Transcript tab, if the transcript is protein-coding.
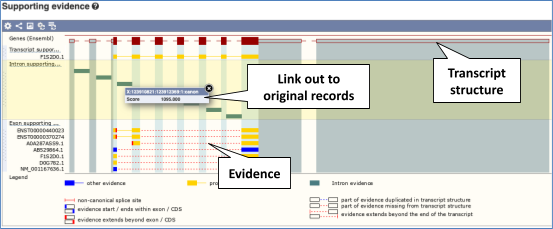
Transcript evidence
For detailed information on the support for this transcript, click on Supporting evidence.
Viewing the transcript sequence
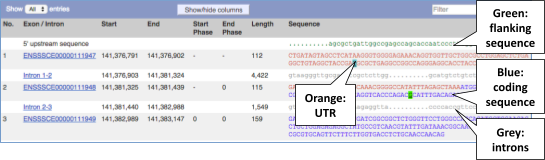
Exon sequence
Click on Sequence: Exons in the left-hand panel.
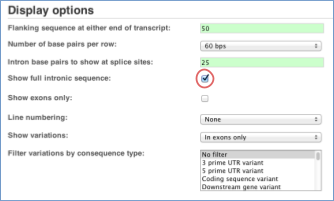
You may want to change the display (for example, to show more flanking sequence, or to show full introns). In order to do so click on the Configure this page button in the left-hand panel and change the display options accordingly.
cDNA sequence
Click on Sequence: cDNA in the left-hand panel to see the spliced transcript sequence.
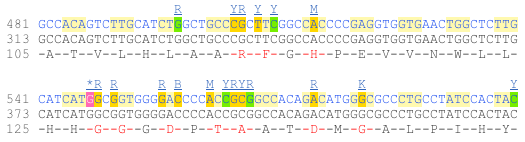
UnTranslated Regions (UTRs) are highlighted in dark yellow, codons are highlighted in alternating white and light yellow, and exon sequences are shown in alternating black and blue colours (highlighting where another exon begins). Variants are represented by highlighted nucleotides and clickable IUPAC ambiguity codes representing the variation above the sequence.
Protein information
Click on Protein Information: Protein summary to view domains from Pfam, Superfamily, AlphaFold DB, and more.

Clicking on Domains & features shows a table of this information.
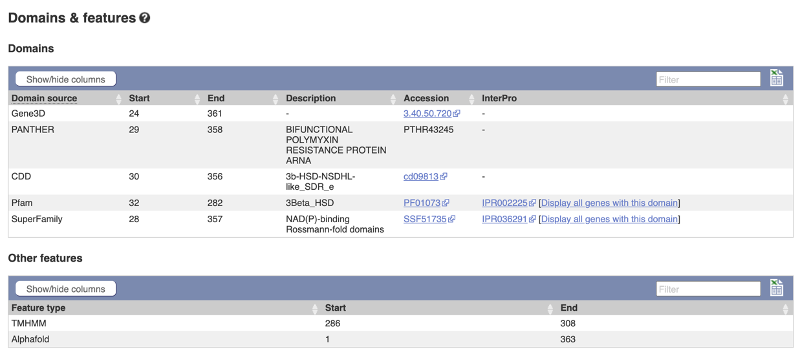
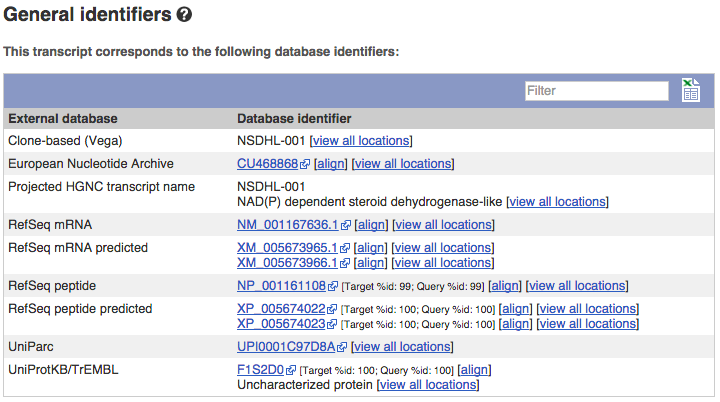
Transcript information in external databases
Click on External References: General identifiers in the left-hand panel. This page shows corresponding information in other databases such as the European Nucleotide Archive (ENA), UniProtKB and Reactome.