
Filter Events by Year
Ensembl Plants Browser Workshop - Decode Life
Course Details
- Lead Trainer
- Louisse Paola Mirabueno
- Associate Trainer(s)
- Event Dates
- 2024-06-17 until 2024-06-20
- Location
- Virtual
- Description
- Work with the Ensembl Outreach team to get to grips with the Ensembl Plants browser, accessing gene and comparative genomics data. Learn also how to download data in bulk via Ensembl's BioMart.
- Survey
- Ensembl Plants Browser Workshop - Decode Life Feedback Survey
Demos and exercises
Species and genome assemblies
Demo: Exploring species and genome assemblies in Ensembl Plants
Homepage
The front page of Ensembl Plants is found at plants.ensembl.org. It contains lots of information and links to help you navigate Ensembl Plants:
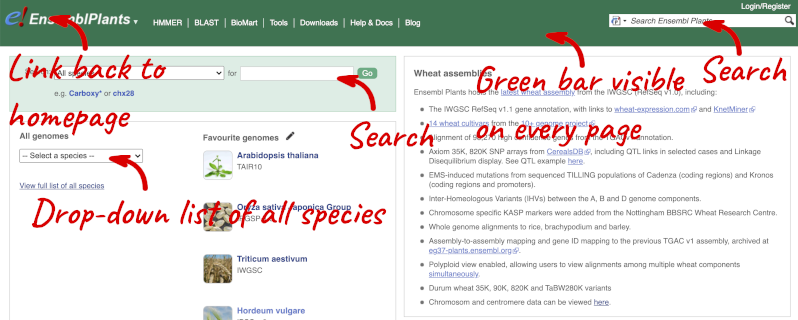
At the top left you can see the current release number and what has come out in this release.
Available species
Click on View full list of all species.
Click on the scientific name of your species of interest to go to the species homepage. We’ll click on Triticum aestivum.
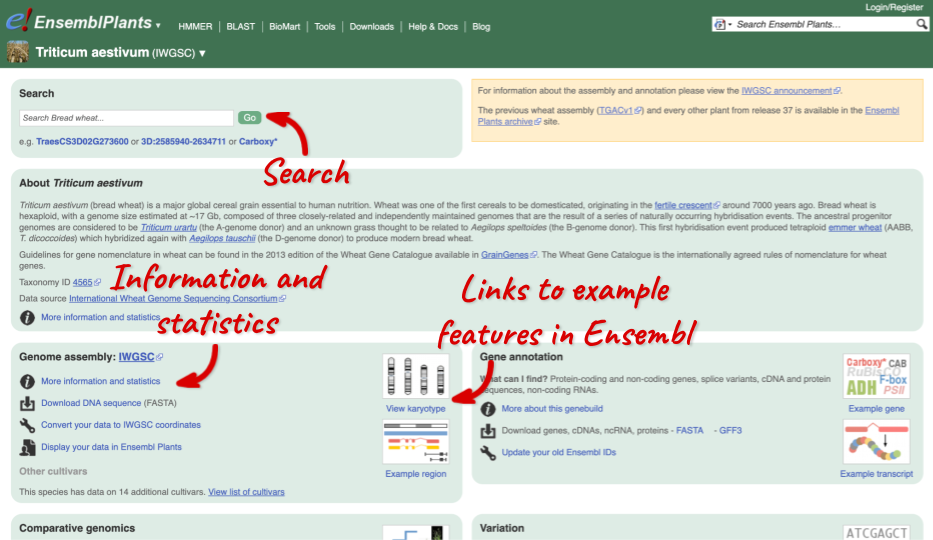
Species information
Here you can see links to example pages and to download flatfiles. To find out more about the genome assembly and genebuild, click on More information and statistics.
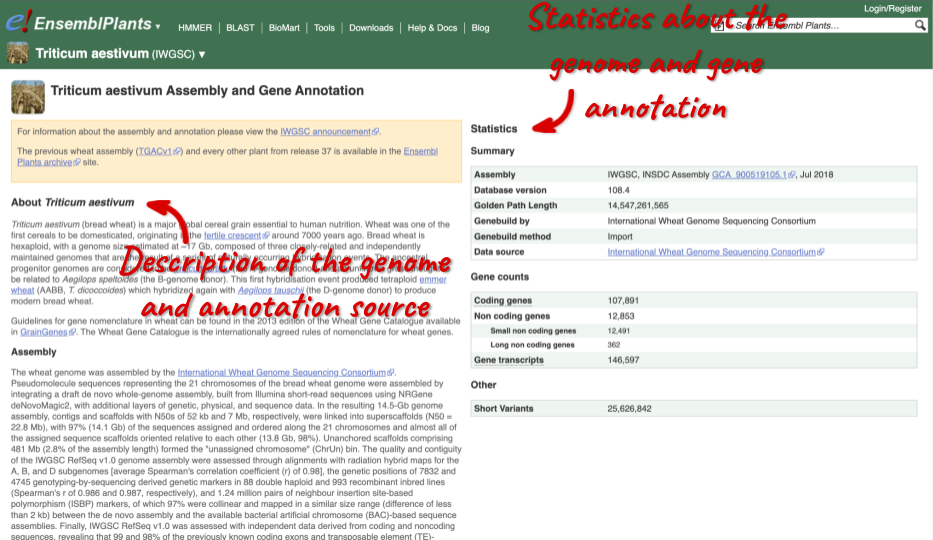
Here you’ll find a detailed description of how to the genome was produced and links to the original source. You will also see details of how the genes were annotated.
Triticum aestivum (wheat) cultivars
-
Are there any additional cultivars available alongside the Triticum aestivum (IWGSC) reference genome?
-
Find the description of the wheat assembly. Which institute provided the assembly and annotations?
-
How many coding and non-coding genes does the IWGSC assembly have?
-
Are there any other species of the genus Triticum available in Ensembl? If so, which species are they?
- Go to Ensembl Plants and click on Triticum aestivum on the front page of Ensembl Plants to go to the species information page. Under the Genome assembly section of the species page, you will find the number of cultivars in wheat.
There are 14 cultivars.
- Click on More information and statistics in the Genome assembly section and scroll down to the paragraph on Assembly.
The assembly and annotations were generated by the International Wheat Genome Sequencing Consortium (IWGSC).
- Stay on the More information and statistics page. You can find some summary statistics on the right-hand side.
The T. aestivum (IWGSC) assembly has 107,891 coding and 12,853 non-coding genes.
- Go to the Ensembl Plants homepage. Click on View full list of all species in the All genomes panel. Filter the table by entering
Triticumin the text box on the top right-hand corner of the table.Besides T. aestivum are 4 other Triticum species available in Ensembl: Triticum dicoccoides (wild emmer wheat), Triticum spelta (spelt), Triticum turgidum (domesticated emmer wheat) and Triticum urartu (red wild einkorn wheat).
Exploring genomic regions
Demo: Exploring genomic regions in Ensembl Plants
Start at the Ensembl Plants front page. You can search for a region by typing it into a search box, but you have to specify the species.
To bypass the text search, you need to input your region coordinates in the correct format, which is chromosome, colon, start coordinate, dash, end coordinate, with no spaces for example: 1D:41289600-41345600. Choose Triticum aestivum from the species drop-down, then type (or copy and paste) these coordinates into the search box.

Press Enter or click Go to jump directly to the Region in detail Page.
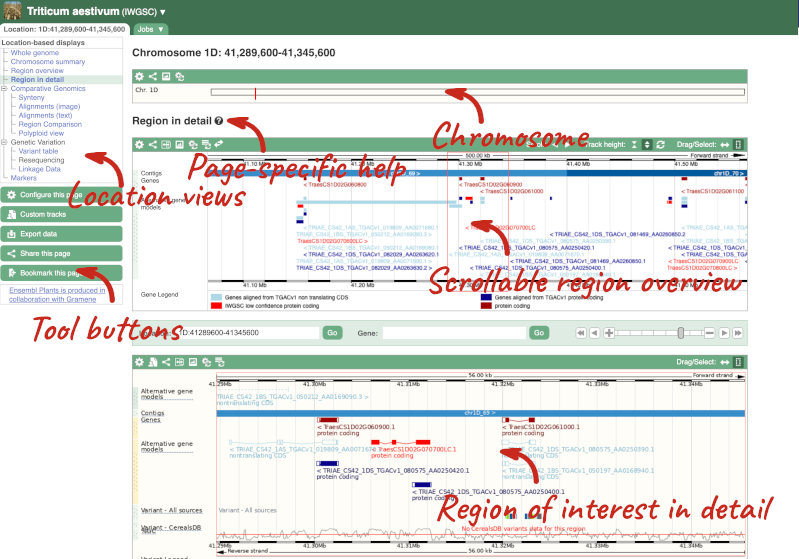
Click on the  button to view page-specific help. The help pages provide text, labelled images and, in some cases, help videos to describe what you can see on the page and how to interact with it.
button to view page-specific help. The help pages provide text, labelled images and, in some cases, help videos to describe what you can see on the page and how to interact with it.
The Region in detail page is made up of three images, let’s look at each one in detail.
- The first image shows the chromosome:

The region we’re looking at is highlighted on the chromosome. You can jump to a different region by dragging out a box in this image. Drag out a box on the chromosome, a pop-up menu will appear.
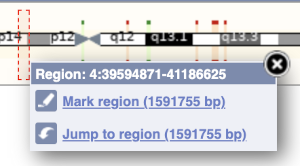
If you wanted to move to the region, you could click on Jump to region (### bp). If you wanted to highlight it, click on Mark region (###bp). For now, we’ll close the pop-up by clicking on the X in the corner.
- The second image shows a 1Mb region around our selected region. This is always 1Mb in human, but the fixed size of this view varies between species. This view allows you to scroll back and forth along the chromosome.
You can also drag out and jump to or mark a region.
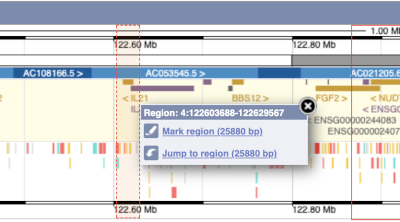
Click on the X to close the pop-up menu.
Click on the Drag/Select button  to change the action of your mouse click. Now you can scroll along the chromosome by clicking and dragging within the image. As you do this you’ll see the image below grey out and two blue buttons appear. Clicking on Update this image would jump the lower image to the region central to the scrollable image. We want to go back to where we started, so we’ll click on Reset scrollable image.
to change the action of your mouse click. Now you can scroll along the chromosome by clicking and dragging within the image. As you do this you’ll see the image below grey out and two blue buttons appear. Clicking on Update this image would jump the lower image to the region central to the scrollable image. We want to go back to where we started, so we’ll click on Reset scrollable image.

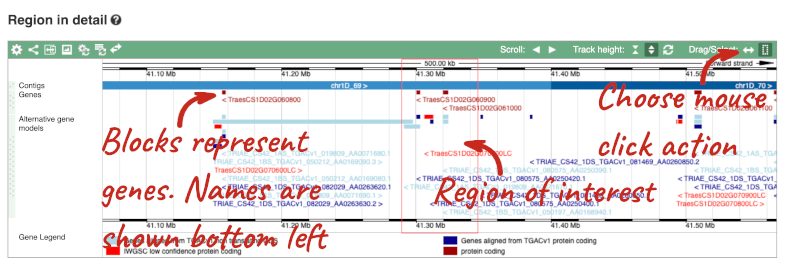
- The third image is a detailed, configurable view of the region.

Here you can see various tracks, which is what we call a data type that you can plot against the genome. Some tracks, such as the transcripts, can be on the forward or reverse strand. Forward stranded features are shown above the blue contig track that runs across the middle of the image, with reverse stranded features below the contig. Other tracks, such as variants, regulatory features or conserved regions, refer to both strands of the genome, and these are shown by default at the very top or very bottom of the view.
You can use click and drag to either navigate around the region or highlight regions of interest, Click on the Drag/Select option at the top or bottom right to switch mouse action. On Drag, you can click and drag left or right to move along the genome, the page will reload when you drop the mouse button. On Select you can drag out a box to highlight or zoom in on a region of interest.
With the tool set to Select, drag out a box around an exon and choose Mark region.
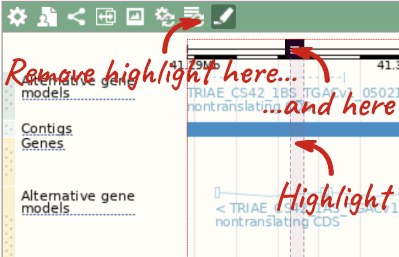
The highlight will remain in place if you zoom in and out or move around the region. This allows you to keep track of regions or features of interest.
We can edit what we see on this page by clicking on the blue Configure this page menu at the left.

This will open a menu that allows you to change the image.
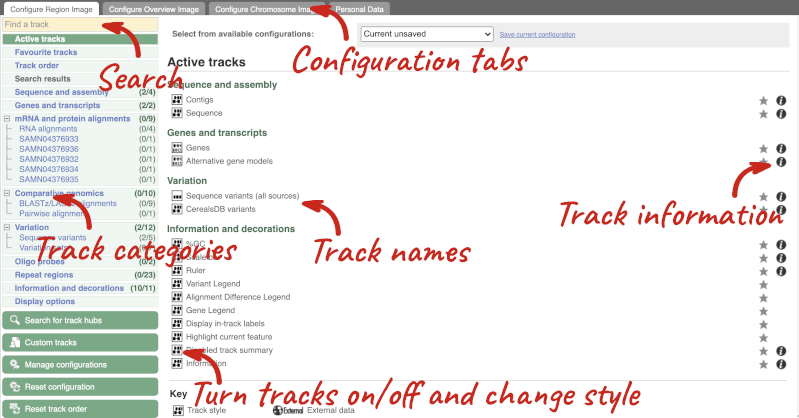
There are thousands of possible tracks that you can add. When you launch the view, you will see all the tracks that are currently turned on with their names on the left and an info icon on the right, which you can click on to expand the description of the track. Turn them on or off, or change the track style by clicking on the box next to the name. More details about the different track styles are in this FAQ.
You can find more tracks to add by either exploring the categories on the left, or using the Find a track option at the top left. Type in a word or phrase to find tracks with it in the track name or description.
Let’s add some tracks to this image. Add:
- EMS-induced mutation variants
- Type I Transposons/LINE (Repeats: Repbase)
Now click on the tick in the top left hand to save and close the menu. Alternatively, click anywhere outside of the menu. We can now see the tracks in the image.
If the track is not giving you can information you need, you can easily change the way the tracks appear by hovering over the track name then the cog wheel to open a menu. To make it easier to compare information between tracks, such as spotting overlaps, you can move tracks around by clicking and dragging on the bar to the left of the track name.

Now that you’ve got the view how you want it, you might like to show something you’ve found to a colleague or collaborator. Click on the Share this page button to generate a link. Email the link to someone else, so that they can see the same view as you, including all the tracks you’ve added. These links contain the Ensembl release number, so if a new release or even assembly comes out, your link will just take you to the archive site for the release it was made on.

To return this to the default view, go to Configure this page and select Reset configuration at the bottom of the menu.
Due to hybridisations in wheat’s evolutionary history, it has a hexaploid genome with related homoeologous regions. We can compare these with the Polyploid view. First, let’s zoom in on the gene TraesCS1D02G061000 by dragging out a box around it and clicking on Jump to region. Now click on the Polyploid view link in the left-hand menu.
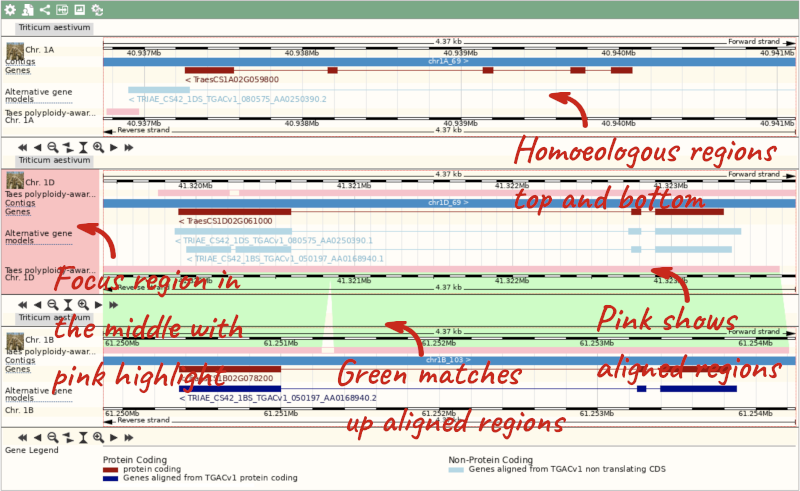
This view also allows us to configure the page, as we could with the main region view, so that we can compare other features between the homoeologous chromosomes.
Exploring a wheat region
-
Go to 2D:378720500-378780600 in Triticum aestivum (wheat).
-
How many genes are in this region? What strand are the genes on? What are the gene IDs for these genes?
-
What tracks can you see that show gene structure? Where did the different tracks come from?
-
Export the genomic sequence for this region.
-
Can you view the genomic alignments of the homoeologous regions? What are the different formats you can export the image as?
-
Go to the Ensembl Plants homepage. Select Search: Triticum aestivum and type
2D:378720500-378780600in the text box. Click Go. -
There are two genes displayed in the Genes track. They are both located on the reverse strand. The IDs are
-
There are two tracks which have mapping to this gene: Genes and Alternative gene models. Click the track names for more information on their source.
-
Click Export data in the left-hand menu. Leave the default parameters as they are. Click Next>. Click on Text. Note that the sequence has a header that provides information about the genome assembly, the chromosome, the start and end coordinates and the strand. For example:
>2D dna:chromosome chromosome:IWGSC:2D:378720500:378780600:1 -
Click on Polyploid view in the left hand menu to view the homoeologous regions. Click on Export image. This will open a pop-up menu of the different image formats you can export, which are PNG and PDF.
Genes and transcripts
Demo: Exploring genes and transcripts in Ensembl Plants
You can find out lots of information about Ensembl genes and transcripts using the browser. If you’re already looking at a region view, you can click on any transcript and a pop-up menu will appear, allowing you to jump directly to that gene or transcript.

Alternatively, you can find a gene by searching for it. You can search for gene names or identifiers, and also phenotypes or functions that might be associated with the genes.
We’re going to look at the Arabidopsis thaliana PAI1 gene. From plants.ensembl.org, type PAI1 into the search bar and click the Go button.
The gene tab
Click on PAI1 from the search hits. The Gene tab should open:
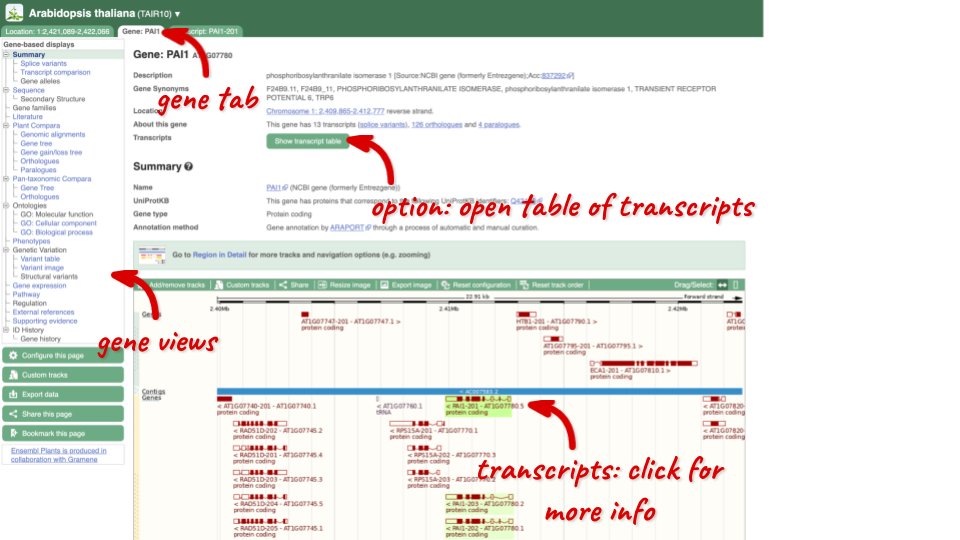
This page summarises the gene, including its location, name and equivalents in other databases. At the bottom of the page, a graphic shows a region view with the transcripts. We can see exons shown as blocks with introns as lines linking them together. Coding exons are filled, whereas non-coding exons are empty. We can also see the overlapping and neighbouring genes and other genomic features.
There are different tabs for different types of features, such as genes, transcripts or variants. These appear side-by-side across the blue bar, allowing you to jump back and forth between features of interest. Each tab has its own navigation column down the left hand side of the page, listing all the things you can see for this feature.
Let’s walk through this menu for the gene tab. How can we view the genomic sequence? Click Sequence at the left of the page.

The sequence is shown in FASTA format. The FASTA header contains the genome assembly, chromosome, coordinates and strand (1 or -1) – this gene is on the negative strand.

Exons are highlighted within the genomic sequence, both exons of our gene of interest and any neighbouring or overlapping gene. By default, 600 bases are shown up and downstream of the gene. We can make changes to how this sequence appears with the blue Configure this page button found at the left. This allows us to change the flanking regions, add variants, add line numbering and more. Click on it now.

Once you have selected changes (in this example, Show variants and Line numbering) click at the top right.
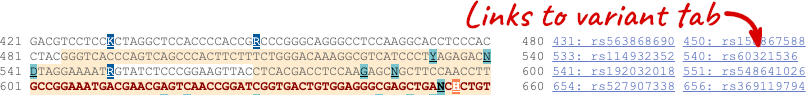
You can download this sequence by clicking in the Download sequence button above the sequence:
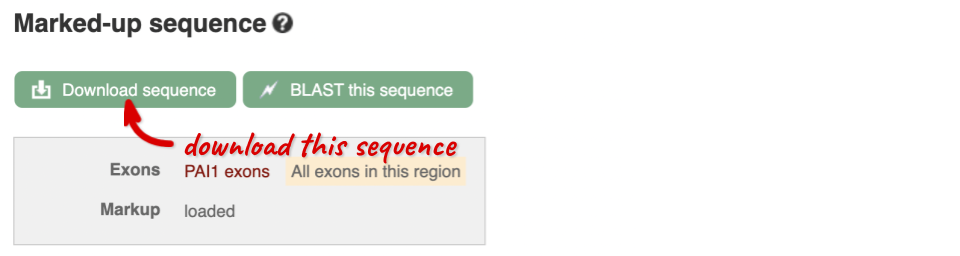
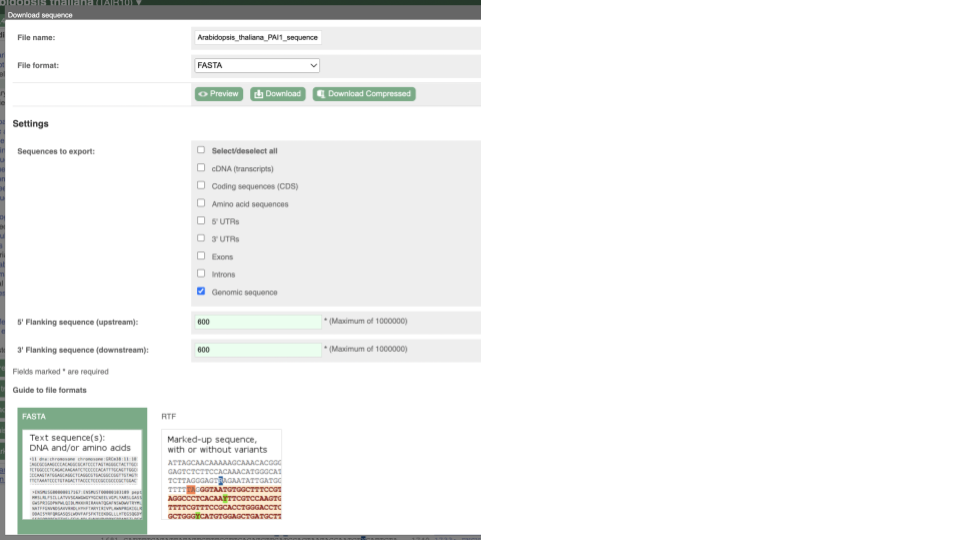
This will open a dialogue box that allows you to pick between plain FASTA sequence, or sequence in RTF, which includes all the coloured annotations and can be opened in a word processor. If you want run a sequence analysis tool, download as FASTA sequence, whereas if you want to analyse the sequence visually, RTF is best for this. This button is available for all sequence views.
To find out what the protein does, have a look at GO terms from the Gene Ontology consortium. There are three pages of GO terms, representing the three divisions in GO: Biological process (what the protein does), Cellular component (where the protein is) and Molecular function (how it does it). Click on GO: Biological process to see an example of the GO pages.
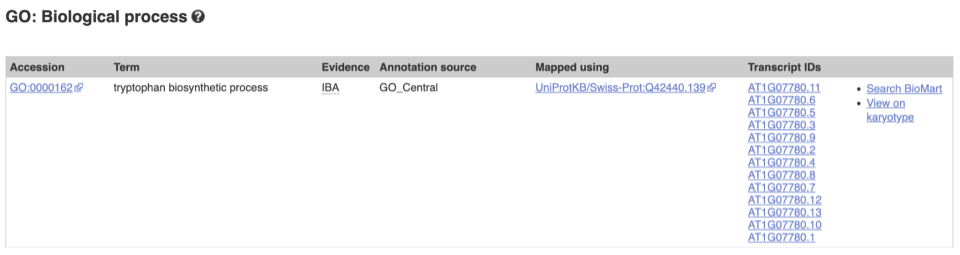
Here you can see the functions that have been associated with the gene. There are three-letter codes that indicate how the association was made, as well as links to the specific transcript they are linked to.
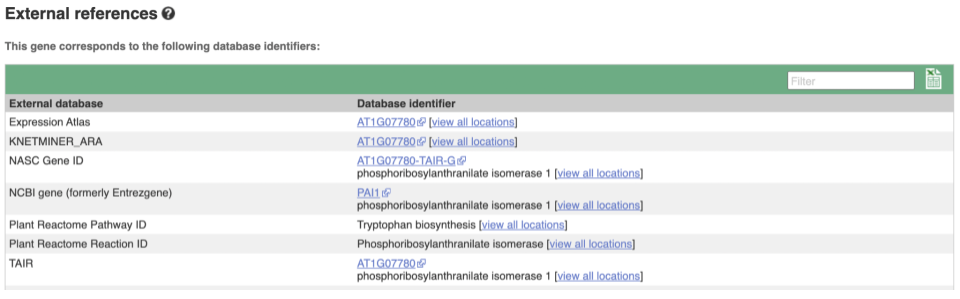
We also have links out to other databases which have information about our genes and may focus on other topics that we don’t cover, like Expression Atlas or UniProtKB. Go up the left-hand menu to External references:
Demo: The transcript tab
We’re now going to explore the different transcripts of PAI1. Click on Show transcript table at the top.
![]()
![]()
Here we can see a list of all the transcripts of PAI1 with their identifiers, lengths and biotypes. Click on the ID of the Ensembl Canonical transcript, PAI1-211.
You are now in the Transcript tab for PAI1-211. We can still see the gene tab so we can easily jump back. The left hand navigation column provides several options for the transcript PAI1-211 - many of these are similar to the options you see in the gene tab, but not all of them. If you can’t find the thing you’re looking for, often the solution is to switch tabs.
Click on the Exons link. This page is useful for designing RT-PCR primers because you can see the sequences of the different exons and their lengths.
![]()
You may want to change the display (for example, to show more flanking sequence, or to show full introns). In order to do so click on Configure this page and change the display options accordingly.
Now click on the cDNA link to see the spliced transcript sequence with the amino acid sequence. This page is useful for mapping between the RNA and protein sequences, particularly genetic variants.
![]()
UnTranslated Regions (UTRs) are highlighted in dark yellow, codons are highlighted in light yellow, and exon sequence is shown in black or blue letters to show exon divides. Sequence variants are represented by highlighted nucleotides and clickable IUPAC codes are above the sequence.
Next, follow the General identifiers link at the left. Just like the External References page in the gene tab, this page shows links out to other databases such as RefSeq, UniProtKB, PDBe and others, this time linked to the transcript or protein product, rather than the gene.
![]()
If you’re interested in protein domains, you could click on Protein summary to view domains from Pfam, PROSITE, Superfamily, InterPro, and more. These are all plotted against the transcript sequence, with the exons shown in alternating shades of purple at the top of the page. Alternatively, you can go to Domains & features to see a table of the same information.
![]()
![]()
Exploring the CCD7 gene in Arabidopsis thaliana
-
Find the Arabidopsis thaliana CCD7 gene on Ensembl Plants. On which chromosome and which strand of the genome is this gene located?
-
Where in the cell is the CCD7 protein located?
-
What is the source of the assigned gene name?
-
How many transcripts does it have? How long is its longest transcript (in bp)? How long is the protein it encodes? How many exons does it have? Are any of the exons completely or partially untranslated?
- Go to the Ensembl Plants homepage (http://plants.ensembl.org/). Select A. thaliana from the species list and type
CCD7in the search box. Click Go and click on the gene ID AT2G44990. You can find the strand orientation and the location under Summary in the Gene tab.The A. thaliana CCD7 gene is located on chromosome 2 on the forward strand.
- Click on GO: Cellular component in the left-hand panel.
The protein is located in the chloroplast and plastid.
- Click on Summary in the side menu.
The gene name is assigned and imported from NCBI gene (formerly Entrezgene).
- Click on Show transcript table.
There are 3 transcripts. The longest one is 2005 bp and the length of the encoded protein is 622 amino acids.
Click on the transcript ID AT2G44990.3 in the transcript table. You can find the number of exons in under in the summary information at the top of the page.
It has 6 exons.
Click on Sequence: Exons in the left-hand panel.
The first and last exons are partially untranslated (sequence shown in orange). This can also been seen from the fact that in the transcript diagrams on the Gene Summary and Transcript Summary pages the boxes representing the first and last exon are partially unfilled.
Finding a Triticum aestivum gene
-
Search for
Oxygen evolving enhancer proteinfrom the Ensembl Plants homepage and narrow down your search to Triticum aestivum. How many genes are there with this name in wheat? Why do you think this is? What chromosomes are they on? -
Go to the gene on chromosome 2B. How many protein-coding transcripts does this gene have? What is a “canonical transcript”?
-
Click on the canonical transcript. How many exons does this transcript have? Export the protein sequence of this transcript in the FASTA format.
- Start at the Ensembl Plants homepage. Choose Triticum aestivum from the species drop-down, type
Oxygen evolving enhancer proteininto the search box then click Go.There are two genes named TraesCS2D02G248400 and TraesCS2B02G270300. This is because of the hybridisations in wheat’s evolutionary history. You can see that the two genes occur on chromosomes 2B and 2D.
- Click on the gene on chromosome 2B to go to the Gene tab. If the transcript table is hidden, click on Show transcript table to see it.
There are 2 protein coding transcripts.
Mouse over the Ensembl Canonical flag in the transcripts table to find a description.
The Ensembl canonical transcript is a single transcript chosen for each gene in each species. It is the most highly conserved, most highly expressed, has the longest coding sequence and is represented in other key resources (e.g. NCBI, UniProt)
- Click on TraesCS2B02G270300.2 in the transcript table. You can find the number of exons in the summary description at the top of the Summary page, or you can count the number of boxes (boxes represent exons, lines represent introns) in the Summary diagram.
TraesCS2B02G270300.2 has 2 exons.
Go to Sequence: Protein In the left-hand panel.
Click on the green Download sequence button above the protein sequence. Select FASTA from the drop-down in the pop-up menu and download the sequence to your local machine.
Comparative genomics
Demo: gene trees and homology predictions
Plants Compara
Gene trees
Let’s look at the homologues of Triticum aestivum (wheat) TraesCS3D02G007500. Open Ensembl Plants, search for the gene and go to the Gene tab.
Click on Plant compara: Gene tree, which will display the current gene in the context of a phylogenetic tree used to determine orthologues, paralogues and homoeologues.

Funnels indicate collapsed nodes. We can expand them by clicking on the node and selecting Expand this sub-tree from the pop-up menu.
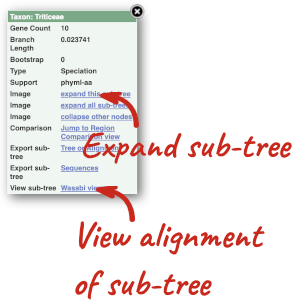
We can also see the protein alignment of the sub-tree by clicking on Wasabi viewer, which will open a pop-up:
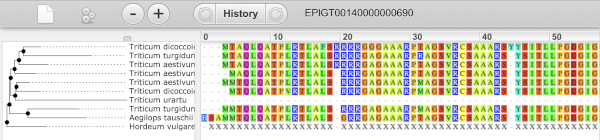
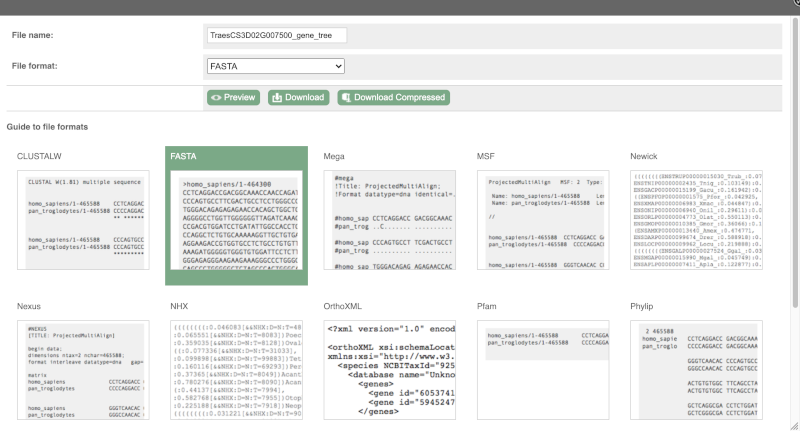
You can download the tree in a variety of formats. Click on the download icon ![]() in the bar at the top of the image to get a pop-up where you can choose your format.
in the bar at the top of the image to get a pop-up where you can choose your format.
Homologues
We can look at homologues in the Orthologues, Paralogues and homoeologues pages, which can be accessed from the left-hand menu. If there are no orthologues, paralogues or homoeologues, then the name will be greyed out. Click on Plant compara: Orthologues to see the orthologues available in plants.
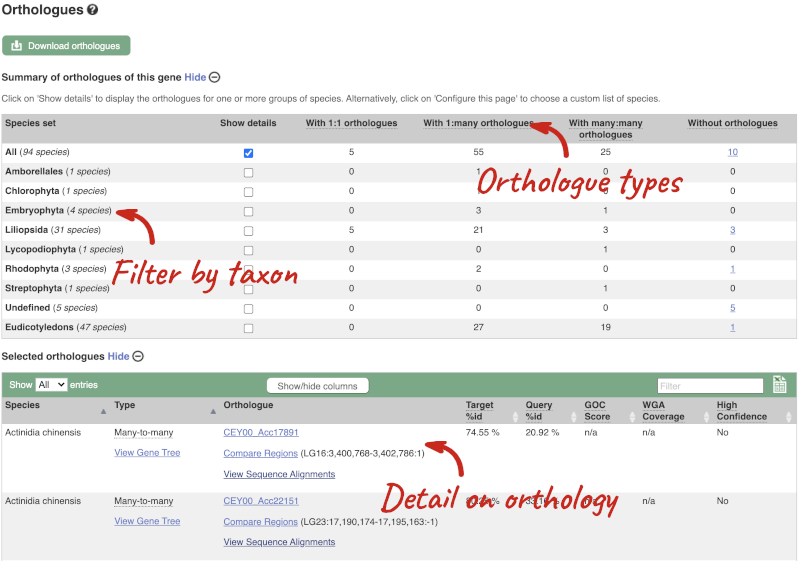
Choose to see only Eudicotyledons orthologues by selecting the box. The table below will now only show details of Eudicotyledons orthologues. Let’s look at Brassica oleracea.
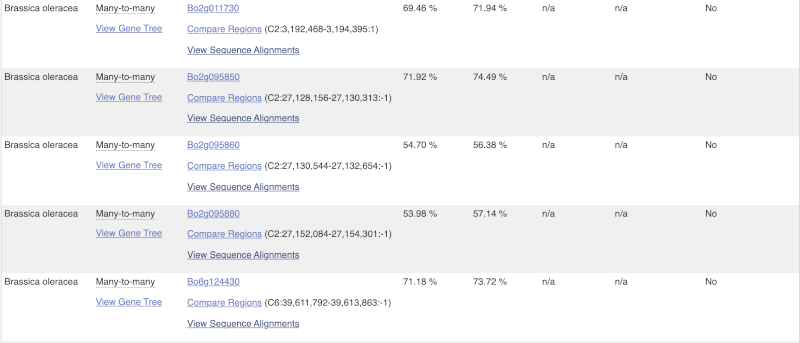
Here we can see there is a many-to-many relationship between the wheat and B. oleracea orthologues. Links from the orthologue allow you to go to alignments of the orthologous proteins and cDNAs. Click on View Sequence Alignments then View Protein Alignment for the first B. oleracea orthologue.
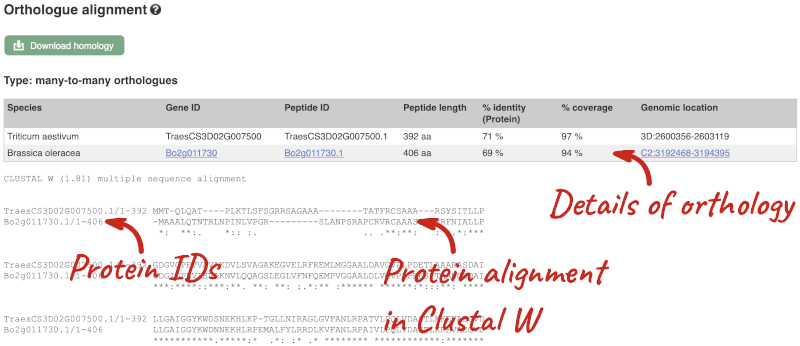
The paralogue page and homoeologue pages are structured in the same way as the orthologue page.
Demo: Whole-genome alignments
Alignments in the Region in Detail view
Let’s look at some of the comparative genomics views in the Location tab. Go to the region 6B:291753000-291966000 in Triticum aestivum (wheat). We can look at individual species comparative genomics tracks in this view by clicking on Configure this page.
Select BLASTz/LASTz alignments from the left-hand menu to choose alignments between closely related species. Turn on the alignments for Triticum dicoccoides (wild emmer), Triticum turgidum (domesticated emmer wheat) and Triticum urartu (red wild einkorn wheat).
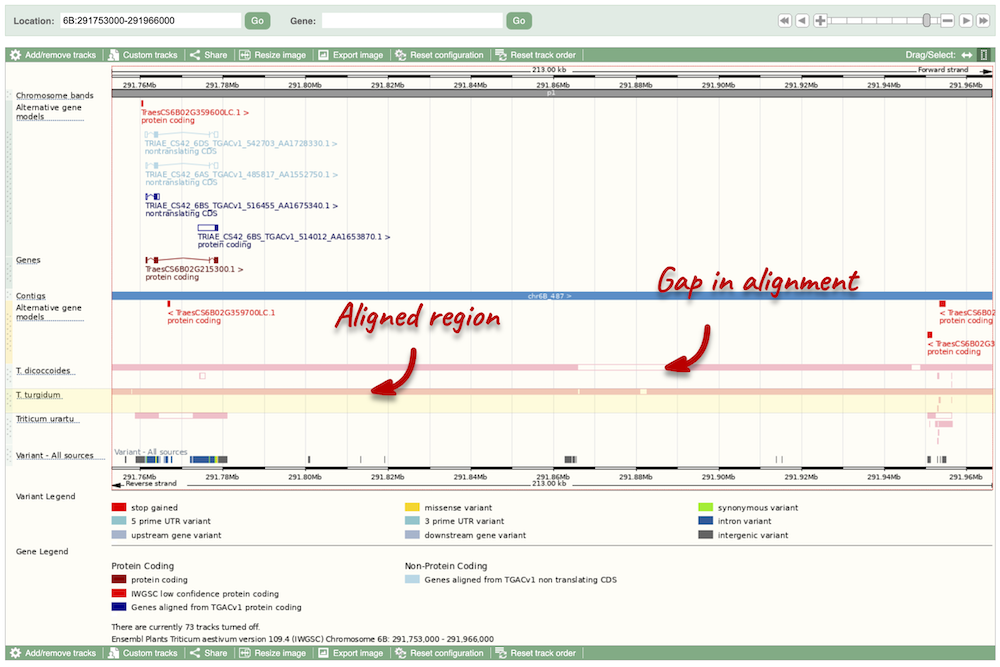
The alignment is greatest between closely related species. We can see that T. turgidum has the most similar sequence to T. aestivum, followed by T. dicoccoides, and T. urartu has the largest gaps in the alignment.
Sequence alignments
We can also look at the alignment between species or groups of species as text. Click on Comparative Genomics: Alignments (text) in the left-hand menu.
Click on Select an alignment to open the alignment menu. Select T. turgidum from the alignments list then click Go.
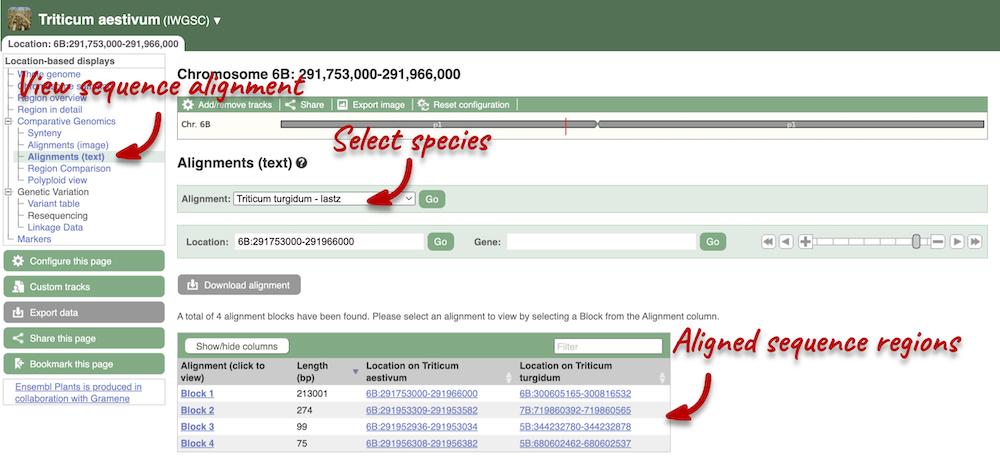
In this case there are 4 blocks aligned of different lengths, some of which correspond to the region we saw unaligned in the image. Click on Block 1.
You will see a list of the regions aligned, followed by the sequence alignment. Click on Display full alignment. Exons are shown in red (you may need to scroll down the page to see the first exon).
Region comparison
To compare with both contigs visually, go to Comparative Genomics: Region Comparison.
To add species to this view, click on the green Select species or regions button. Choose T. turgidum again then close the menu.
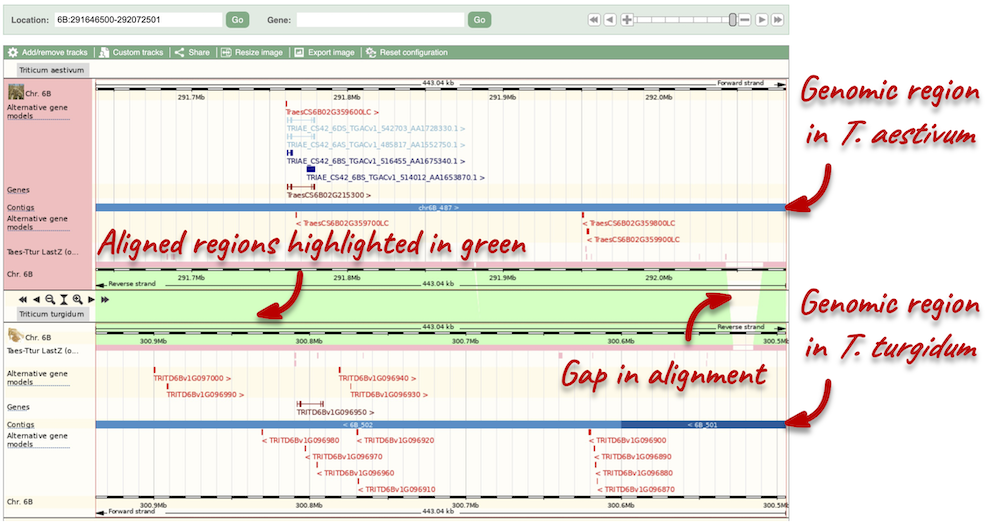
Polyploid view
For polyploids, a Polyploid view will be available for you to compare homologous chromosomes. Genomes for each chromosome are displayed graphically in the lower panel. Your reference chromosome is shown in the first panel. Orange bars show aligned regions between the homologous chromosomes. Aligned regions are also connected and highlighted in green.
Synteny
We can view large-scale syntenic regions from our chromosome of interest. Click on Comparative Genomics: Synteny in the left-hand menu and select T. turgidum* from the **Change species drop-down in the right-hand side.

Black linking lines indicate sequences are oriented in the same directed, red linking lines indicate the sequences are inverted.
Homologues and gene trees for the Triticum aestivum (wheat) RHT1 gene
Go to Ensembl Plants and answer the following questions:
-
How many orthologues are predicted for the Triticum aestivum (wheat) gene RHT1 (gene ID TraesCS4D02G040400) gene in Liliopsida?
-
How much sequence identity does the Secale cereale (rye) protein have to the maize one?
-
Download the alignment in Nexus format.
-
Open the gene tree for the wheat RHT1 gene. What is the gene tree ID?
-
How many speciation and duplication nodes does the phylogeny have?
Go to the Ensembl Plants homepage, select Triticum aestivum from the Species drop-down and search for TraesCS4D02G040400. Click through to the Gene tab. On the Gene tab, click on Plant Compara: Orthologues at the left-hand side of the page to see all the orthologous genes.
- These are the orthologues in the Liliopsida:
- 24 1-to-1
- 9 1-to-many
- 0 many-to-many
- Filter the table by entering
Secale cerealein the filter box on the top right-hand corner of the table.The percentage of identical amino acids in the rye protein (the orthologue) compared with the gene of interest (i.e. wheat RHT1; the target species/gene) is 98.71%. This is known as the Target %ID. The identity of the gene of interest (wheat RHT1) when compared with the orthologue (the rye gene, i.e. the query species/gene) is 97.91% (the query %ID).
Note the differences in the values of the Target and Query % ID reflects the different protein lengths for the genes. -
Click on View Sequence Alignments in the Orthologue column. Select View Protein Alignment from the pop-up menu. Click on the green Download homology button above the table and select Nexus. Click on Download or Download Compressed to save the alignment on your local machine.
- Go to Plant Compara: Gene tree in the left-hand menu. You can find the gene tree ID above the phylogeny.
The gene tree ID is EPlGT00940000163877.
- You can find some summary statistics below the gene ID.
There are 418 speciation nodes and 149 duplication nodes.
Exploring whole-genome alignments for Triticum aestivum (wheat)
Go to Ensembl Plants and answer the following questions:
-
Find the TraesCS2D02G080000 gene in Triticum aestivum (wheat). What is the function for this gene and what are its coordinates?
-
Go to the Location tab. Turn on the LASTZ-net alignment tracks for Arabidopsis thaliana, Zea mays (corn) and Sorghum bicolor (great millet). Are there any regions where you can see gaps in in some of the species alignments?
-
Go to the Region comparison view and compare to A. thaliana. What occurs at this gap in the alignment?
-
Export the Block 2 alignment between T. aestivum and A. thaliana in ClustalW format.
- Go to the Ensembl Plants homepage. Select Triticum aestivum from the Species drop-down, enter
TraesCS2D02G080000in the search box and click Go. Open the Gene tab.The gene description is as follows: Ascorbate peroxidase, ROS homeostasis, Chloroplast protection, Carbohydrate metabolism, Plant architecture, Fertility maintenance. This was projected from Oryza sativa (Os07g0694700).
- Go the Location tab in the top left-hand corner. Click on CConfigure this page in the side menu. Open Comparative genomics: BLASTz/LASTz alignments in the pop-up menu. Turn on the tracks for Arabidopsis thaliana, Zea mays (corn) and Sorghum bicolor (great millet) in the Normal style. Save and close the pop-up menu
There is alignment across most of the coding regions, with some gaps occurring in all 3 species. These gaps map with the intronic regions of the T. aestivum gene.
- Click on Comparative Genomics: Region Comparison in the left-hand menu. Go to the Select species or regions button and add A. thaliana. Save and close the menu.
The gap in the alignment translates to the intronic regions of the T. aestivum gene.
- Go to Comparative Genomics: Alignments (text) and select A. thaliana from the Alignment drop-down. Click on the green Download alignment button and select ClustalW. Download the file to your local machine either in a compressed format, or as it is by clicking the green Download button above the file format preview.
Variation
Demo: The gene tab
View all variants within a gene sequence
In any of the sequence views shown in the Gene and Transcript tabs, you can view variants on the sequence. You can do this by clicking on Configure this page from any of these views.
Let’s take a look at the Gene sequence view for TraesCS4A02G446800 in wheat. Search for TraesCS4A02G446800 and go to the Sequence view.
If you can’t see variants marked on this view, click on Configure this page and select Show variants: Yes and show links.

Find out more about a variant by clicking on it.
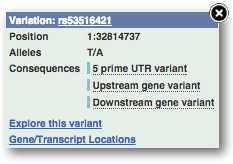
You can add variants to all other sequence views in the same way.
You can go to the Variation tab by clicking on the variant ID. For now, we’ll explore more ways of finding variants.
View all variants within a gene in tabular format
To view all the sequence variations in table form, click the Variant table link at the left of the gene tab
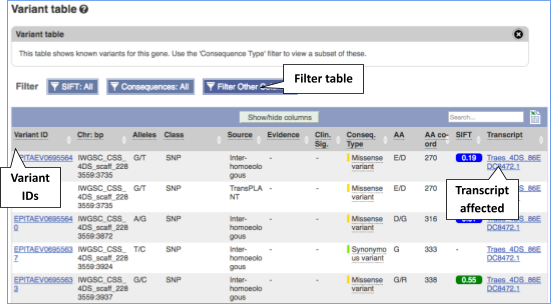
You can filter the table to only show the variants you’re interested in. For example, click on Consequences: All, then select the variant consequences you’re interested in.
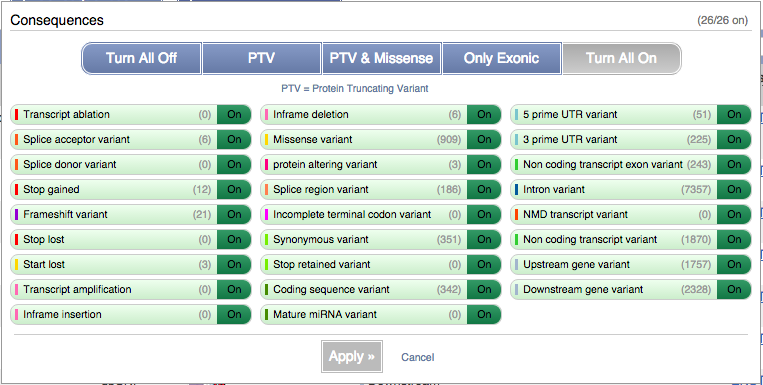
You can also filter by other columns such as, Evidence or Class.
Demo: The location tab
Visualise variants within a region
Let’s have a look at variants in the Location tab. Click on the Location tab in the top bar.
Configure this page and open Variation from the left-hand menu.
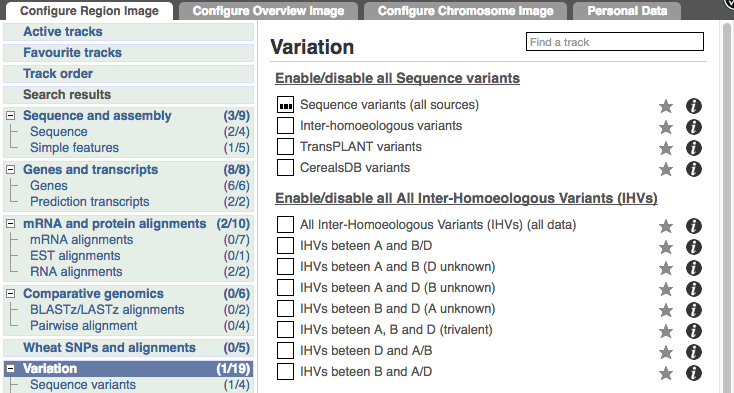
There are various options for turning on variants. You can turn on variants by source, by frequency, presence of a phenotype or by individual genome they were isolated from. Turn on the following all sequence variants in Normal.
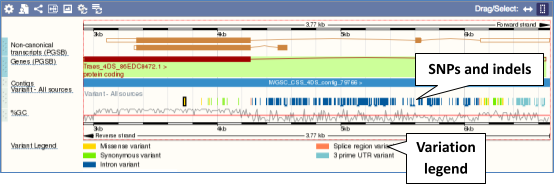
Click on a variant to find out more information. It may be easier to see the individual variants if you zoom in.
Demo: The variant tab
Variant summary
Let’s have a look at a specific variant. The easiest way to find a specific variant is to search for it. Search for BA00249348 and click through to the Variant tab.
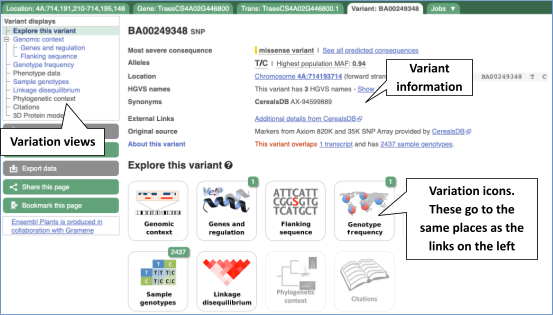
Variant consequences specific features
The icons show you what information is available for this variant. Click on Genes and regulation, or follow the link at the left.

This variant is found in TraesCS4A02G446800 only.
Genotype frequency
Let’s look at population genetics. Either click on Explore this variant in the left hand menu then click on the Genotype frequency icon, or click on Genotype frequency in the left-hand menu.

Genotype frequency
We can see which strains these genotypes were observed in by going to Sample Genotypes.

Investigating a variant in wheat
-
Search for the variant
BA00369602in Triticum aestivum on Ensembl Plants. Is this variant known by any other names? -
What gene is affected by this variant? What is the amino acid change?
-
Which cultivars have the alternative base at this locus?
- Start at the homepage and enter BA00369602 into the search box and select Triticum aestivum from the drop-down list. Click on the Gene ID BA00369602 in the search results to get to the variation homepage.
Under Synonyms, you can see that the variant is also known as AX-94448191 in CerealsDB.
- Click on Genes and regulation.
The variant is a missense variant on TraesCS2D02G303800, where it gives a glycine to aspartic acid (G/D) change at transcript position 406.
- Click on Sample genotypes. Scroll down the table to see if there are any cultivars with the A allele in the genotype column.
All of the cultivars listed have the genotype
G|G.
VEP
Demonstration of the VEP web interface
Input
We have identified three variants on wheat chromosome 4B:
C -> T at 240206468
C -> G at 240199078
C -> T at 240212229
We will use the Ensembl VEP to determine:
- Have my variants already been annotated in Ensembl?
- What genes are affected by my variants?
- Do any of my variants affect gene regulation?
Click on Tools in the top green bar from any Ensembl Plants page, then Variant Effect Predictor to open the input form:
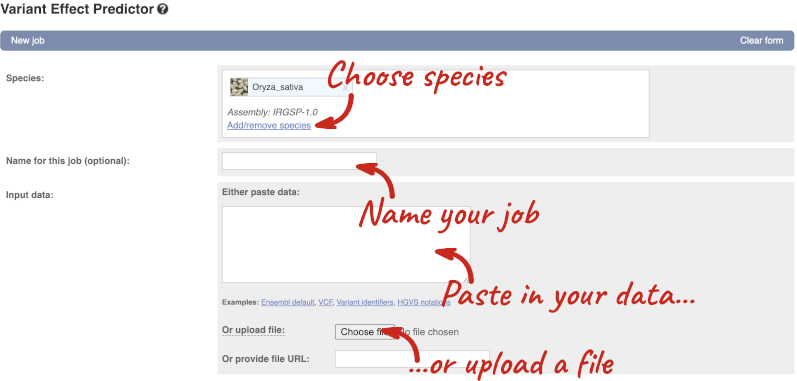
Click on Add/remove species and search for Triticum aestivum to choose it.
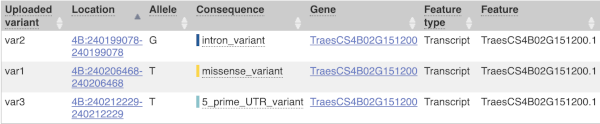
The data is in VCF:
chromosome coordinate id reference alternative
Put the following into the Paste data box:
4B 240206468 var1 C T
4B 240199078 var2 C G
4B 240212229 var3 C T
The VEP will automatically detect that the data is in VCF.
Additional configurations
There are further options that you can choose for your output. These are categorised as Identifiers, Variants and frequency data, Additional annotations, Predictions, Filtering options and Advanced options. Let’s open all the menus and take a look.
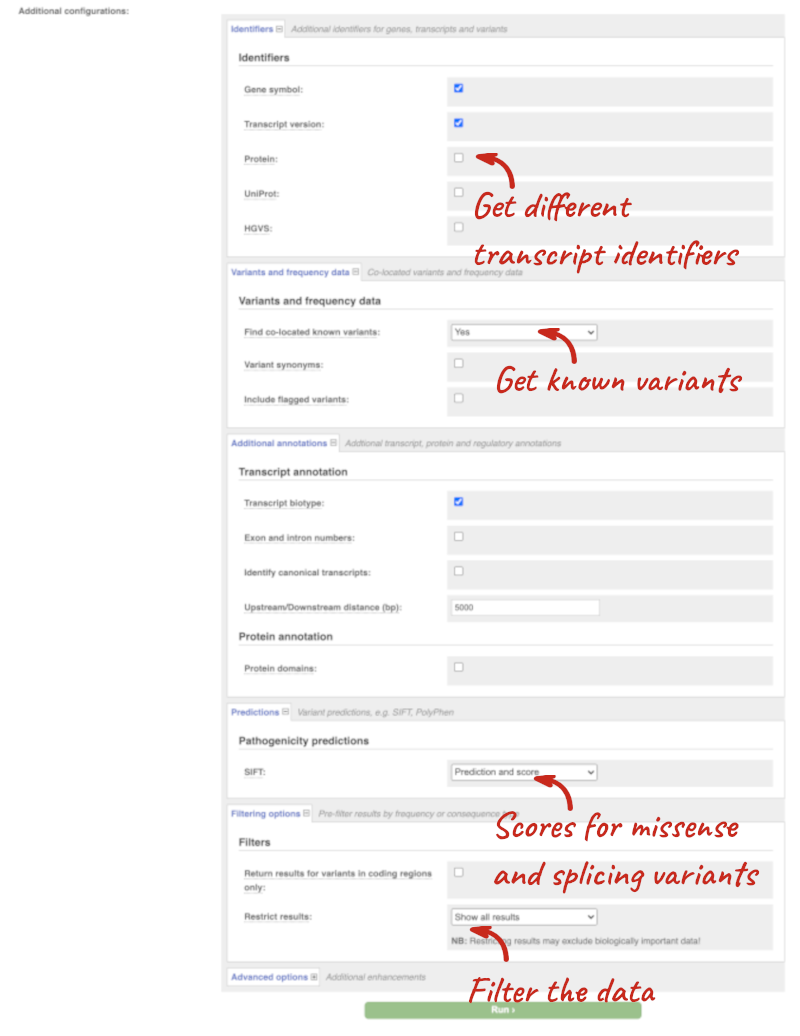
Hover over the options to see definitions.
When you’ve selected everything you need, scroll right to the bottom and click Run.

The display will show you the status of your job. It will say Queued, then automatically switch to Done when the job is done, you do not need to refresh the page. You can edit or discard your job at this time. If you have submitted multiple jobs, they will all appear here.
Click View results once your job is done.
Results
In your results you will see a graphical summary of your data, as well as a table of your results.
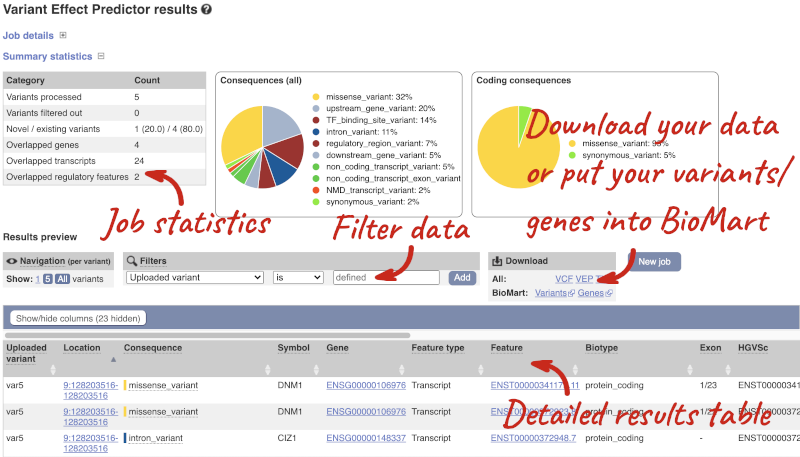
The results table is enormous and detailed, so we’re going to go through the it by section. The first column is Uploaded variant. If your input data contains IDs, like ours does, the ID is listed here. If your input data is only loci, this column will contain the locus and alleles of the variant. You’ll notice that the variants are not neccessarily in the order they were in in your input. You’ll also see that there are multiple lines in the table for each variant, with each line representing one transcript or other feature the variant affects.
You can mouse over any column name to get a definition of what is shown.
The next few columns give the information about the feature the variant affects, including the consequence. Where the feature is a transcript, you will see the gene symbol and stable ID and the transcript stable ID and biotype. The IDs are links to take you to the gene or transcript homepage.
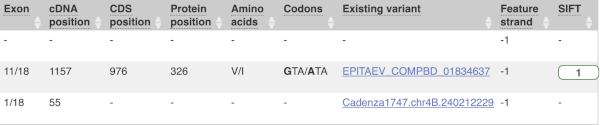
This is followed by details on the effects on transcripts, including the position of the variant in terms of the exon number, cDNA, CDS and protein, the amino acid and codon change and pathogenicity scores. Where the variant is known, the ID of the existing variant is listed, with a link out to the variant homepage. The pathogenicity scores are shown as numbers with coloured highlights to indicate the prediction, and you can mouse-over the scores to get the prediction in words.
Above the table is the Filter option, which allows you to filter by any column in the table. You can select a column from the drop-down, then a logic option from the next drop-down, then type in your filter to the following box. We’ll try a filter of Consequence, followed by is then missense_variant, which will give us only variants that change the amino acid sequence of the protein. You’ll notice that as you type missense_variant, the VEP will make suggestions for an autocomplete.

You can export your VEP results in various formats, including VCF. When you export as VCF, you’ll get all the VEP annotation listed under CSQ in the INFO column. After filtering your data, you’ll see that you have the option to export only the filtered data. You can also drop all the genes you’ve found into the Gene BioMart, or all the known variants into the Variation BioMart to export further information about them.
Web VEP analysis of variants in Triticum aestivum (wheat)
You have done whole-genome sequencing and variant-calling experiments for Triticum aestivum. You have a VCF file with a small subset of variants from this experiment. Analyse the variants in this file with the VEP tool in Ensembl Plants and determine the following:
-
How many variants were analysed? How many are novel?
-
How many genes and transcripts are affected by variants in this file?
-
Do any of the variants have different consequences for different transcripts?
-
Filter the table to find variants with high impact. How many variants have high impact? Why do you think missense variants are not classified as high impact?
-
Can you export all the results to a VCF file? Compare it to the input VCF file to see what information the VEP adds.
Go to any Ensembl Plants page and click on Tools in the navigation bar at the top of the page. Click on Variant Effect Predictor and change your species to Triticum aestivum by clicking on Change species.
Enter a descriptive name for your VEP job. If you have downloaded the variant file to your local machine, click on Choose file to upload. Alternatively, you can paste the URL for the file into the Or provide file URL: box. Click Run at the bottom of the page. When your job is done, click View reesults.
-
20 variants were analysed, of which 1 is novel.
-
Only 1 gene is affected by variants in this file. The gene has 2 transcripts and both are affected by the variants.
- You can find a list of calculated variant consequences and their impact here.
Yes, the novel variant results in a stop_lost in TraesCS3A02G301400.1 and is a downstream_gene_variant for TraesCS3A02G301400.2.
- Use the filters to view only variants with HIGH impact (you may need to add the column under Show/hide columns at the top of the table if you cannot find it). The filters are found above the detailed results table in the middle. Select Impact and is from the drop-down menus. Then type
HIGHinto the box; this will autocomplete. Click Add.There are 3 variants with high impact and all three are stop altering. Missense variants are not classified as high impact, because they do not always have significant impacts on protein functions. Usually the protein is still produced. In contrast, stop altering variants affect the protein length, and therefore likely affect the protein function.
- At the top right of the table there is an option to download data. Click on VCF for the All option. Open the VCF file you have downloaded in a text editor. You can see that VEP adds annotation in the INFO column of the VCF file.
BioMart
Demo: BioMart
Follow these instructions to guide you through BioMart to answer the following query:
- What genes are found on chromosome 5D, between 19400000 and 21300000 in wheat?
- What are the NCBI Gene IDs for these genes?
- Are there associated functions from the GO (gene ontology) project that might help describe their function?
- What are their cDNA sequences?
Step 1: Choose the database and dataset
Click on BioMart in the top header of any Ensembl Plants page to open BioMart
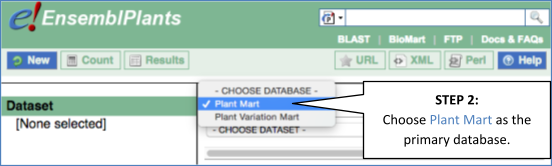
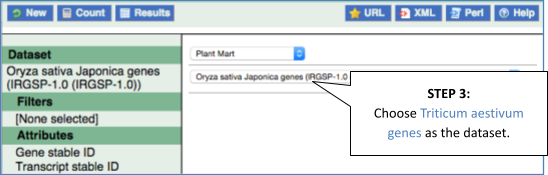
Step 2: Choose appropriate filters
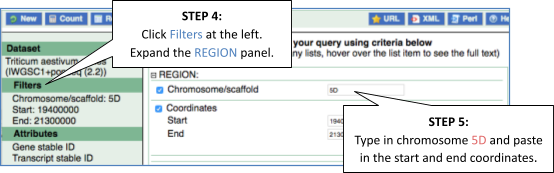
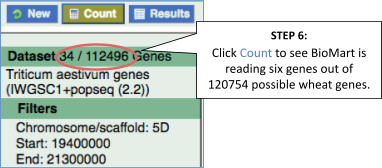
Step 3.1: Select attributes (features)
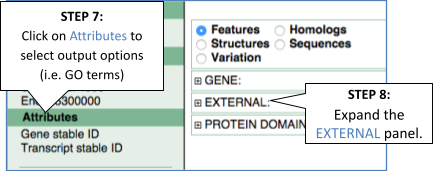


Step 4.1: Get the results
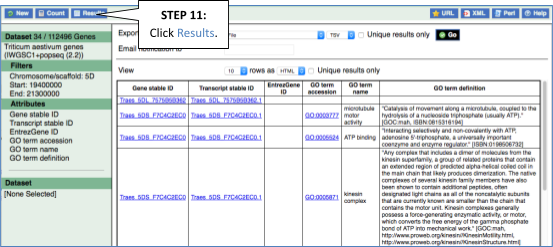
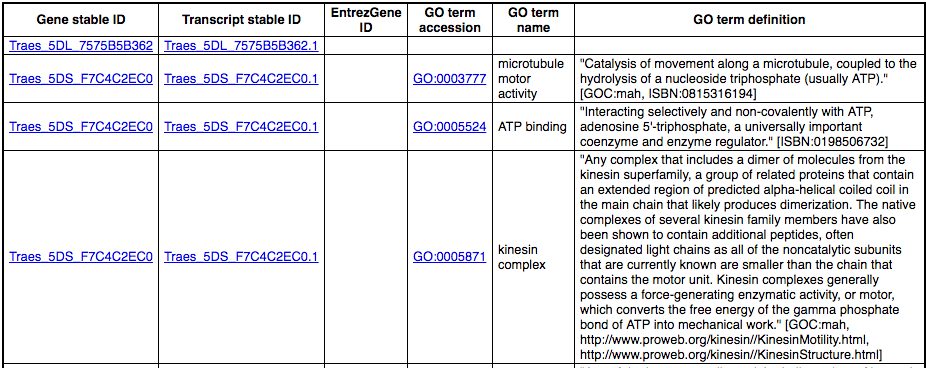
Why are there multiple rows for one gene ID? For example, look at the first few rows.
Step 3.2: Select attributes (sequences)
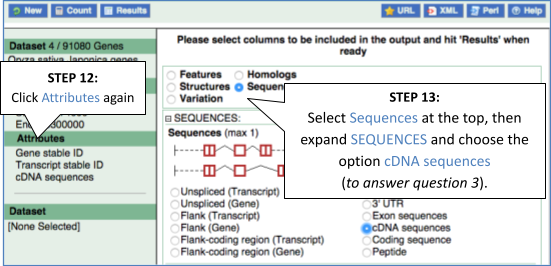
Step 4.2: Get the results
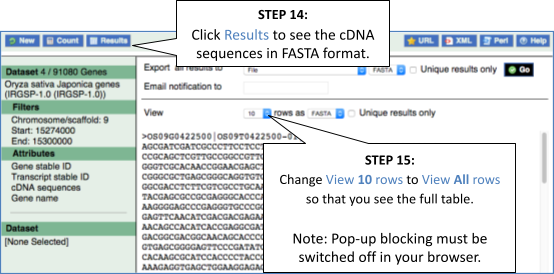
Note: you can use the Go button to export a file.
What did you learn about the wheat genes in this exercise?
Could you learn these things from the Ensembl browser? Would it take longer?
For more details on BioMart, have a look at this publication: Kinsella RJ, Kähäri A, Haider S, et al. Ensembl BioMarts: a hub for data retrieval across taxonomic space. Database : the Journal of Biological Databases and Curation. 2011 ;2011:bar030. DOI: 10.1093/database/bar030. PMID: 21785142; PMCID: PMC3170168.
Get genes by protein domain
Go to Ensembl Plants and find the following information:
Retrieve the protein sequences (in FASTA format) of all Triticum aestivum (wheat) genes that have an NCBI Gene ID, that are protein-coding and with Transmembrane helices. Do a count after the selection of each filter to check the number of genes remaining in your dataset. Export the results of the sequences and select Gene description and Source of gene name as headers.
-
Click on BioMart on the navigation bar at the top of the page. Click the New button on the toolbar on the top left-hand corner, choose the Ensembl Plants Genes database and Triticum aestivum genes (IWGSC) dataset. Now, filter for the genes with NCBI Gene ID only:
- Click on Filters in the left panel, expand the GENE section by clicking on the + box. Select with NCBI Gene ID under Limit to genes (external references)…. Make sure the box next to the filter is ticked, otherwise the filter won’t work. Click the Count button on the toolbar.
This will give you 92 Genes.
Now filter further for genes that are protein-coding by selecting Gene type – protein_coding and click again on Count.
This still gives you 92 Genes, meaning that all genes you have previously filtered are protein-coding.
Finally, filter for genes that have a signal peptide domains. Expand the PROTEIN DOMAINS AND FAMILIES section by clicking on the + box. Select Transmembrane helices – Only under Limit to genes….
There are 79 genes on the bread wheat genome that contain NCBI Gene IDs and protein coding with signal domains.
-
Go to Attributes on the left-hand panel. Select Sequences from the options on the right. Expand the SEQUENCES section by clicking on the + box and select Peptide. Select the appropriate header information from the HEADER INFORMATION section: Gene description and Source of gene name.
- Click on Results on the toolbar and the sequence will be shown as FASTA format. You can export the sequence by downloading it directly to your local machine or sending it to your email.
Export homologues
For a list of Hordeum vulgare genes, export the Triticum aestivum orthologues.
HORVU.MOREX.r3.2HG0191020
HORVU.MOREX.r3.2HG0134140 HORVU.MOREX.r3.2HG0144470 HORVU.MOREX.r3.1HG0064460 HORVU.MOREX.r3.1HG0008890
Go to plants.ensembl.org and click on the link Tools at the top of the page. Click on BioMart.
Click New. Choose the Ensembl Plants Genes database. Choose the Hordeum vulgare genes (MorexV3_pseudomolecules_assembly) dataset.
Click on Filters in the left panel. Expand the GENE section by clicking on the + box. Enter the gene list in the Input external references ID list box. Select Gene stable ID(s) [e.g. HORVU.MOREX.r3.1HG0000030] from the drop-down menu.
Click on Attributes in the left panel. Select the Homologues attributes page. Expand the ORTHOLOGUES section by clicking on the + box. Select Triticum aestivum gene stable ID.
Click Results.






